Dansk beskrivelse af ISS-side
Dette er dokumentation for en separat side, der viser informations om Den Internationale Rumstation(ISS)s moduler. ISS-siden henter information om modulerne af ISS vha. SPARQL-forespørgsler til de to semantiske datakilde Wikidata og DBpedia.
Først følger en beskrivelse af semantisk webdata efterfulgt af en kort gennemgang af de to datakilder. Endelig følger beskrivelse af, hvordan jeg implementerede et dynamisk setup til at trække data ud af de to kilder.
Semantisk webdata
Semantisk webdata bygger på en ide fra Tim Berners-Lee om, at maskiner skal kunne forstå konteksten af data på internettet. Hvor vi mennesker måske har nemt ved at se, at +4570121416 er et telefonnummer, opfatter en maskine kun en række af tal, der lige så godt kunne være et cpr-nummer eller fødsels- og dødsår for en person. Berners-Lee foreslår derfor, at der skal indsættes opmarkering omkring data, så maskinen kan forstå sammenhængen mellem flere entiteter eller mellem en entitet og en dataværdi.
Semantisk data benytter retningsbestemte relationer mellem to entiteter til at beskrive datastrukturen. F.eks. kan der siges, at en entitet har prædikatet ”hasNephew” til en anden entitet. Pga. relationens tre dele – to entiteter og et prædikat – kaldes sådanne relationer i semantisk data for tripler.
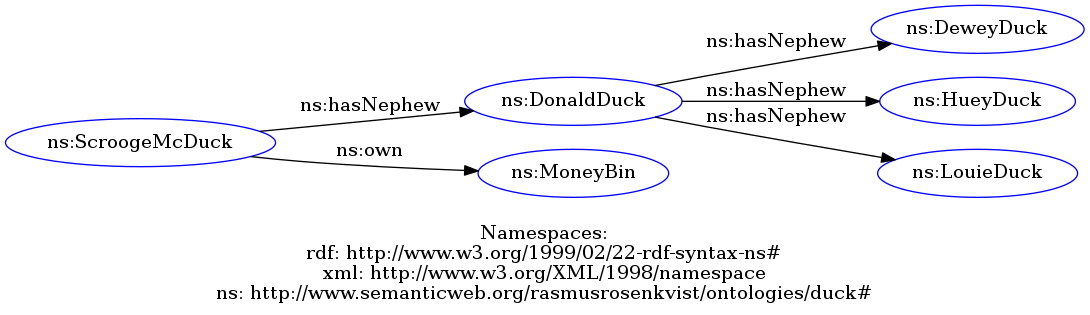
Hvis flere entiteter og prædikater sættes sammen i samme datastruktur, kan de til sidst udgøre en hel graf af sammenhængende data.
Det mest centrale ift. semantisk data er brugen af unikke ID´er for hver entitet og kant. Disse ID´er bygger på den generelle infrastruktur af internettet ved at benytte HTTP og den generaliserede version af URL, URI – Uniform Resource Identifier, så ét ID kan refereres på tværs af internettet og stadig være unik. Det forbindende prædikat benytter også et URI, så det er muligt at bruge fælles begrebsdefinitioner på tværs af mange datasæt, hvis der indsættes den samme URI for samme sammenhæng i hvert datasæt.
Til at søge i semantisk data benyttes sproget SPARQL. Det bygger på mange af de samme ord som SQL, men i SPARQL findes alting ud fra tripler, hvor der kan søges efter de tomme dele af en tripel vha. et spørgsmålstegn. F.eks. kan der søges efter alle entiteter, ”?uncle”, der har udgående prædikat ”hasNephew” til en anden entitet ”?nephew”. Responsen på søgningen bliver så netop de entiteter, der indgår i tripler, der har det pågældende prædikat som centrum.
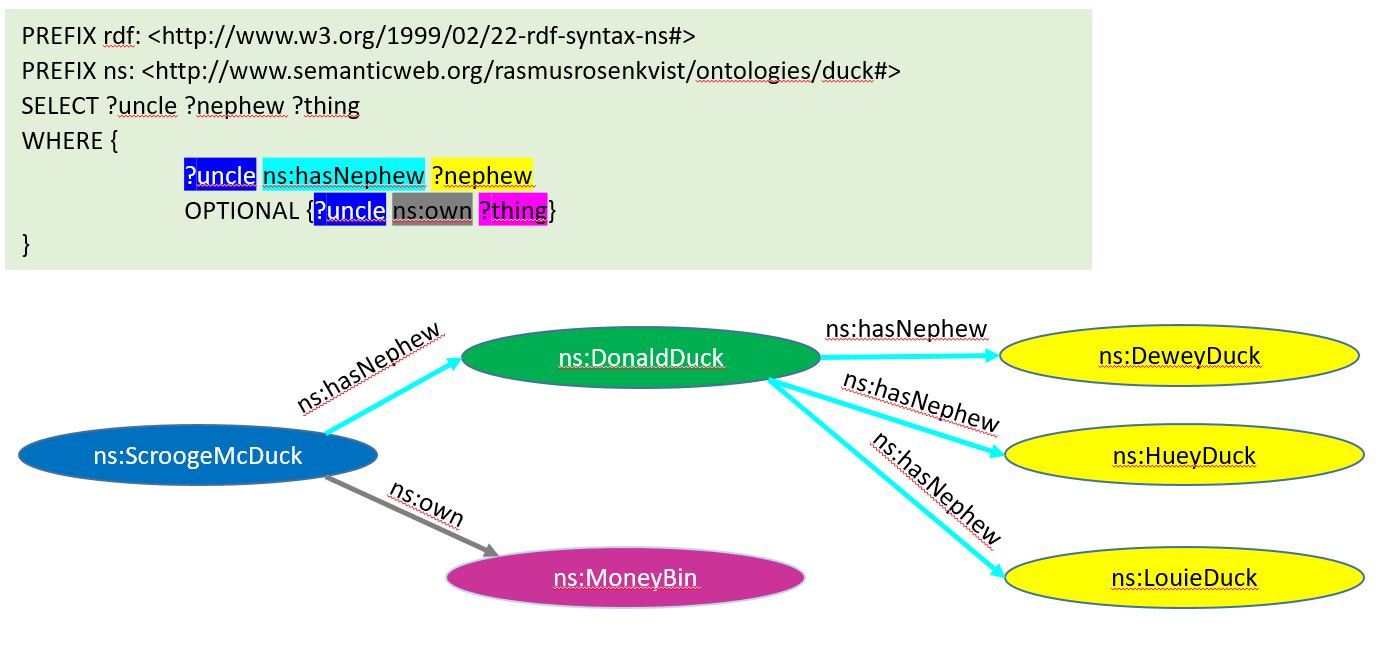
I ovenstående billede er de forskellige dele af søgestrengen markeret med forskellige farver, der går igen i prædikaterne og entiteterne under søgestrengen. Læg mærke til, at DonaldDuck er markeret som grøn, da han både får farven gul fra at være nevø til Scrooge og farven blå fra at være onkel til de tre nevøer. Samme entitet kan altså godt være start- og slutpunkt for søgning vha. SPARQL, og det er muligt at søge baseret på alle tre dele af tripler. Hvis der kunne ville søges efter Anders Ands nevøer, kunne hans URI indsætte som første led af søgningen, mens andet led og tredje del af forespørgslen forblev uændret.
Pga. den globale natur af URI ift. semantisk data kan der søges på tværs af flere online datasæt vha. SPARQL, hvor brugen af én bestemt URI kan benyttes som fælles navngiver.
Implementering
Kildekoden kan findes ved at inspicere siden for ISS-modulerne. Det følgende er meget groft beskrevet, men jeg er mere end villig til at tage en dybere samtale om det - Skriv en besked til mig
Desuden er meget af basiskoden for forespørgslerne hentet fra Wikidatas og DBpedias egne sider for opbygning af forespørgsler.
Venstre del af ISS-side sender en SPARQL-forespørgsel – ”wikidata_Query_for_all_ISS_modules” – afsted til Wikidata ved sideindlæsning for at finde alle nuværende beboelige moduler af rumstationen. Disse returneres som en JSON-array, der efterfølgende udskrives i en HTML-tabel som en række knapper med klassen ” iss_module_button”, der har den fulde URL/URI for modulet som dataværdi. Navnet for modulet udskrives i en kolonne til venstre for knappen.
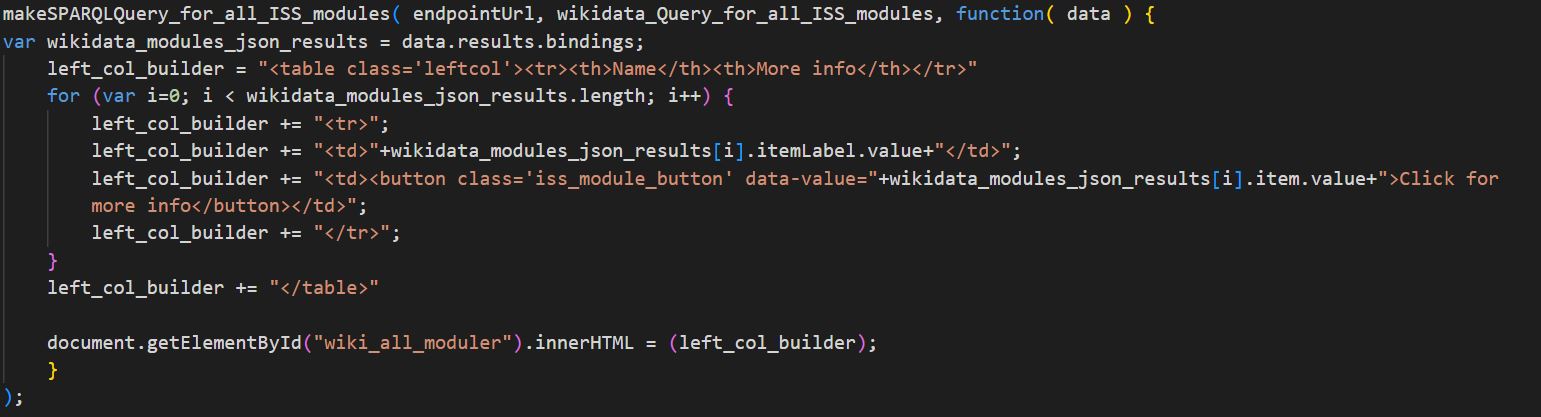
Hvis der trykkes på hvilken som helst knap med klassen ” iss_module_button”, startes den sekundære script på siden, der trækker informationer om det pågældende modul ud. Der er defineret to tomme variabler i scriptet ”wikidata_Qcode” og ”Qcode_to_DBpedia”, hvor den første efter et klik skiftes til selve Q-koden for den pågældende knap.
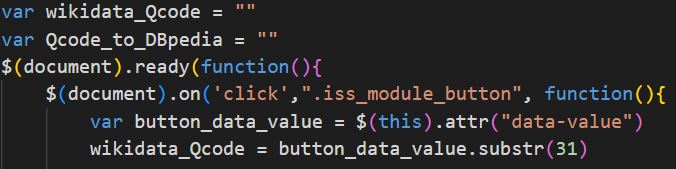
Herefter der kaldes på to funktioner ”wikidata_query” og ”dbpedia_query”, der forespørger henholdsvis Wikidata og DBpedia om Q-kodens modul.
I ”wikidata_query”-funktionen findes alle de moduler, der har forbindelse til det valgte modul sammen med retningen for det pågældende vedhæng. Prædikatet P2789 vedrører forbindelsen mellem det valgte modul og så andre moduler af ISS, så der findes alle de tredje dele af tripler med modulets Q-kode og P2789 ud fra reglerne for SPARQL. Det efterfølgende ”MINUS” vedrører så fjernelsen fra søgeresultatet alle de moduler, der også har fået tilføjet P582, der i Wikidata betyder afslutning – altså de moduler, der er dekoblet fra ISS og brændt op i atmosfæren.
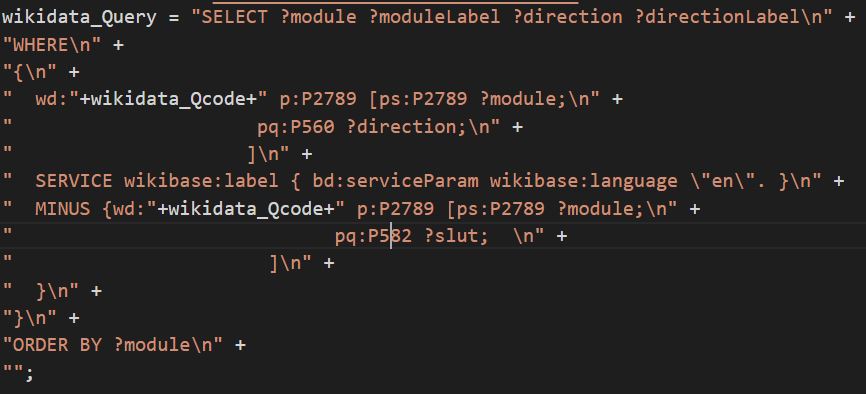
Derefter udskrives igen en HTML-tabel – denne gang i højre del af siden – med knapper af klassen ”iss_module_button”, hvor de andre kolonner i tabellen beskriver nabomodulets navn og retning.
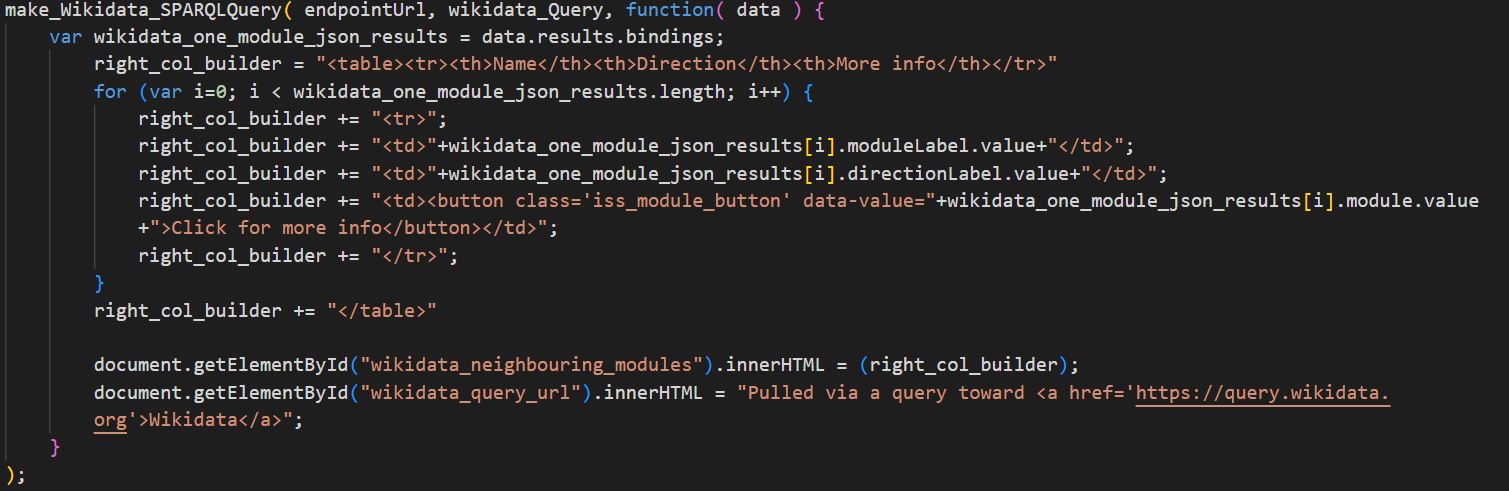
I ”dbpedia_query”-funktionen findes navnet og beskrivelsen af det valgte modul på engelsk. ”owl:sameAs” er det semantiske webs svar på at sige, at denne entitet er præcis lig med en entitet i et andet datasæt, men under et andet navn.
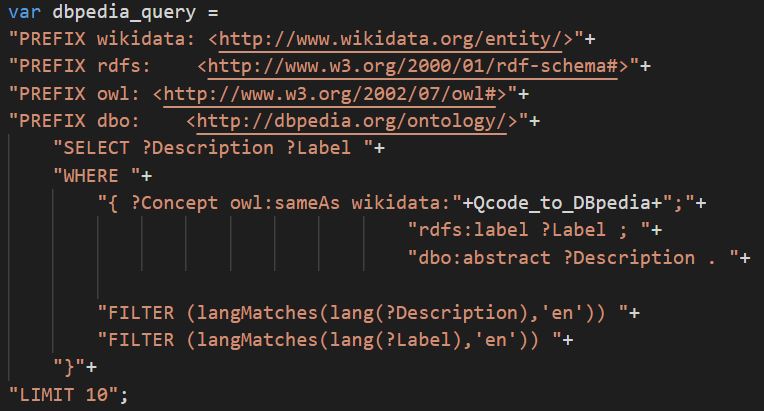
Herefter udskrives navn og beskrivelse i den midterste del af siden.

Ved at knappen for hvert nabomodul også er af klassen ” iss_module_button”, kan der benyttes de samme stykker kode til at bevæge sig mellem modulerne ud fra knapperne i venstre del af siden.